|
编者按:昨天,有一则关于台积电自研芯片的文章刷爆了笔者的朋友圈。行业内的媒体的报道尚算中肯,也就是谈了台积电做了一个什么样的芯片,提供了怎么样的一个Demo,但有些标题党的作者甚至用“台积电要抢高通生意”这样的字眼来吸引读者。无论如何,这都与笔者所了解的台积电不一样。
为了让大家了解“台积电自研芯片”这件事,笔者特意翻译了wikichip的这篇文章,帮助读者理解整件事的真相。
以下为文章正文:
随着基于小芯片(chiplet)的设计从研究转向生产,我们看到了来自工业界的小芯片论文的新流入。本月早些时候在日本京都举行的VLSI 2019上,台积电展示了自己的“小芯片”设计。
据雷锋网的报道,所谓“chiplet”是一种芯片,封装了一个IP(知识产权)子系统。它通常是通过高级封装集成,或者是通过标准化接口使用。至于它们为什么会变得如此重要,这是因为我们的计算和工作类型呈爆炸式增长,目前没有一种全能的办法来应对这些问题。从根本上说,对一流技术的异构集成是延续摩尔定律的一种方式。
使用基于小芯片的设计具有一些显著优点,例如更快的开发周期和更高的产量来降低成本。但它也带来了一系列新的挑战,这些挑战源于在基于小芯片的设计中追求类似单片产品(monolithic-like)的功耗和性能特性。因此,当中的主要挑战是互连和封装技术。虽然这些挑战仍然悬而未决,但已经有多种具有不同性质的解决方案被提出。在超大规模集成电路研讨会上,台积电展示了他们的一些技术,试图解决这些挑战。
台积电试图验证的三个主要特性是:
值得注意的是,此研究和技术验证旨在用于高性能计算。因此,这些内核拥有非常高的时钟,高速率的内部互联速率,以及高密度线路和每比特传输极低功率的芯片间链路(inter-chip links with high-density wires and very low power per bit transfer)。
首先看芯片方面;
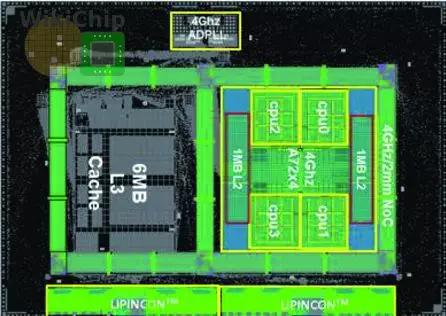
该芯片本身是一种双小芯片设计,但该技术本身可以通过额外的物理层(PHYS)相对容易地扩展到容纳更大数量的小芯片。每个小芯片都是在台积电7纳米节点上制造,拥有15个金属层。裸片本身只有4.4 mm×6.2 mm(27.28 mm2)。台积电采用了四个ARM Cortex-A72核。针对turbo频率大于4GHz电压操作,配备了高性能的cell(7.5T,3p + 3n)并定制设计1级高速缓存单元。还有两个2级缓存块。每个是1 MiB。这些是使用它们的高电流位单元(bitcells)并以半速运行来实现的。此外还有一个大型的6 MiB 3级缓存,使用高密度位单元实现,并以四分之一速度运行。
台积电采用了在高性能芯片中常见增强功能。典型的h-tree被用来将时钟分布的偏差从22ps减少到8ps。高性能时钟偏差以及via towers被广泛用于进一步改善关键路径上的时序。统计显示,整个设计共有五个电压域(voltage domains):0.8V SOC、0.8V ADPLL、0.3-0.8V Lipincon、0.8V L3和0.3-1.2V CPU。该芯片采用全数字锁相环,其抖动小于10ps,用于为CPU、互连和内存生成三个时钟域(clock domains )。
在1.20的电压下,Cortex核可以达到4GHz (signoff).。这个数字是基于运行Dhrystone模式工作负载的核心测量得到的。
其次来看一下网状互连(Mesh Interconnect);
该裸片包括网状互连。互连测试可通过片上分组生成单元(on-die packet generation unit )和分组监控单元(packet monitoring unit)完成。有六个双向触发器(bi-directional flip-flop)网格站(mesh stations)——每个边缘一个,中间两个。这些工作站围绕整个小芯片,间隔大约2毫米。网状互连是1968位宽,并使用具有相反方向信号(opposite direction signals )的逐位交错线路(bit-wise-interleaved wires )在M12和M13中布线,以最小化耦合( minimize coupling)。
总之,片上网状互连(on-die mesh interconnect)可以在4 GHz(0.8 V)到5 GHz(1.2 V)之间正常工作。缓存和Cortex集群都连接到最近的左下角(bottom-left )网格停止点(垂直方向时)。
互连可在0.76V下达到4GHz的频率。
再看一下芯片互联;
每个小芯片上都有两个LIPINCON(Low-voltage-In-Package-INterCONnect简称)接口。每个物理层的测量值仅为0.42 mm×2.4 mm(1.008 mm2)。这些是单端(single-ended),单向(unidirectional),低摆幅接口(low-swing interfaces)。一个接口用作与L3通信的主设备,而第二个接口是用于相反方向的从设备。
与SoC的其他部分不同,由于电源接地(power-ground)噪声问题,专用时钟有一个独立的PLL。每个物理层使用2:1多路复用功能,以便将速度加速到8 Gb / s。每个子通道有两个延迟锁相环( DLL):一个减少PVT变化,另一个用于减少时钟偏差,使系统级芯片和物理层之间的时钟相位对齐。由于使用单相锁相环,因此会采用两个环路——第一个环路锁定进入的时钟周期,并将其分为八个相位,第二个环路将该相位分为16个步骤。换句话说,在4 GHz(250 ps)下,您将看到低于2 ps的分辨率。
在本篇论文中,两个裸片连在一起。第二个小芯片旋转180度,用于LIPINCON PHY基台(abutment)。
芯片本身采用了台积电COWOS(Chip on Wafer on Substrate)2.5D封装技术,也就是将逻辑芯片和DRAM 放在硅中介层(interposer)上,然后封装在基板上。台积电在这里应用,就意味着硅中介层(silicon interposer)将用作安装在其上的两个相同小芯片的基板。
使用硅中介层可以采用更小的凸块(bumps),使得小芯片之间的导线更密集和更低。在这种设计中,使用了一个非常激进的40μm的微凸距,两个裸片之间只有100微米的间隔。
我们最后来看一下技术比较;
在两倍的时钟速度下,物理层运算速度为8GT/s。在互连宽度( interconnect width)为320位时,两个裸片之间的总带宽为320 GB / s。在40μm的bump pitch 下,这实际上是我们在最近的芯片设计中看到的最激进的间距之一,它还可以达到1.6 Tb / s /mm2的数据通量。下表对比了AMD和Intel最近的两款小芯片设计。值得一提的是,英特尔之前曾提到过EMIB(嵌入式多芯片互连),其bump pitches为45μm,甚至将电流密度增加一倍至35μm。
但是,到目前为止,我们还没有发现任何能够证明这些功能的英特尔产品(包括Kaby Lake G)。
编后语:看完整个报道,我们可以看到,这个台积电做芯片的事情,其实就是台积电展现一下他们在最近热门的chiplet方面的实力。换句话说,这与某些读者所理解的自研芯片,不是同一个概念。你对这又有着怎样的了解和看法?欢迎留言讨论!
注:本文由公众号半导体行业观察(ID:icbank)翻译自「wikichip」。
| 

 发表于 2019-6-25 14:39:11
发表于 2019-6-25 14:39:11